Fair use underpins how AI models learn
Fair use is at the heart of how AI models learn. Courts have long held that using copyrighted material is allowed when it serves a new purpose. AI training does exactly that. Models learn patterns and relationships rather than storing or retrieving works. Copyright law protects creators while giving AI the room it needs to innovate.
How AI models learn
Generative AI, including large language models (LLMs), train on large datasets to understand how words and ideas connect. The more information an AI model can learn from, the better it gets at drafting the accurate, relevant responses that can drive breakthroughs that benefit society. As the debate about AI and copyright continues, it helps to start with the basics of exactly how models are trained.
Step 1
The training process begins with the model processing millions, if not billions, of text sequences. This involves analyzing vast amounts of raw text from training data and breaking it down into smaller parts.
Step 2
These smaller parts, called tokens, represent words, sub-words, or even characters that the model can process.

Step 3
Each token is then assigned a numerical representation, called an “embedding,” that captures its meaning and statistical relationship across the training dataset. This helps transform complex data that humans can read into numbers that a computer can process.

Step 4
LLMs transform words and their relationships into vectors — points in a multi-dimensional space that form a kind of map the model uses to understand and generate language. This mathematical map doesn’t need to store the original content — instead, it focuses on the relationships between words in order to generate new material.
Step 5
Once training is complete, the model uses what it has learned to generate original responses. It predicts one word at a time based on the statistical relationships encoded during training, assembling sentences that reflect patterns drawn from the dataset as a whole. This process allows LLMs to create original outputs without need to retrieve, replicate, or store the underlying training text.

Step 6
For example, if a user asks “Do queens live in a castle?” the model would reference the relationships between similar key words. Because “queen” is closely related to “king” and “royal” in its training data and “castle” is strongly associated with “monarchs” and “residences,” the model recognizes these concepts frequently occur together. It then responds: “Yes, as royals, kings and queens often live in castles.
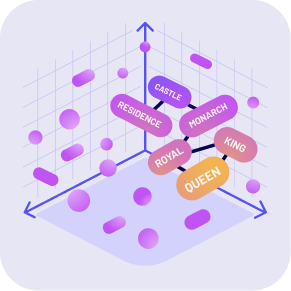
4 key takeaways
AI models generate new works based on patterns
AI models learn by breaking down text and other data into smaller parts. They don’t need to store, retrieve, or reproduce the original materials they’ve been trained on.
Law protects expression, not ideas or competition
U.S. copyright law protects creative expression, not underlying ideas, facts, or patterns. Similarly, the law doesn’t protect against new competition — only against copying existing expression.
Courts back using copyrighted materials in AI training
Courts have found that transformative uses — including AI training on whole books or datasets — are lawful when they serve a new purpose and don’t replace the original works in the market.
Restricting AI training threatens American innovation
Limiting access to training data would undermine the development of AI technologies and run counter to the goals of copyright, which seeks to promote creativity and progress.
Understanding the AI & copyright landscape
Fair use is a core tenet of U.S. copyright law and is essential to how we build on existing ideas to create something entirely new. The doctrine draws a clear line between protected creative expression and the facts that fuel learning, support research, and foster discovery.